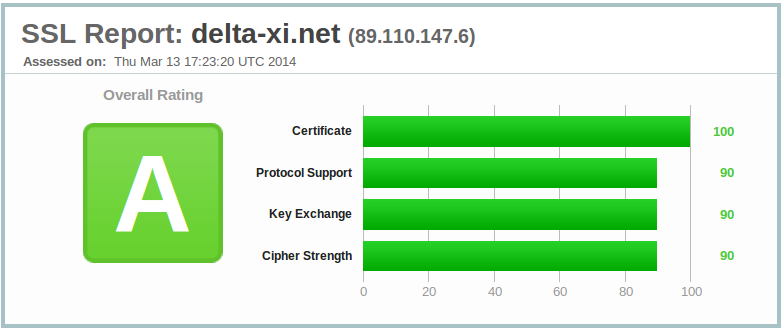
This is somehow offtopic - but if you're a guitarist, you may consider having a look.
Do you really know your fretboard? Interestingly, there are plenty of awesome guitarists out there who really know how to pull the strings - playing fast, playing accurate, using exotic techniques. But when it comes to theory of harmonics, incredibly many guitarists throw the towel (at least, that's what I have experienced). Most of them have heard of (and played) different modes, but when you jam around and tell them "Okay Fred, give me some F sharp Locrian lick around this riff", you may run into troubles.
Beyond tapping, sweeping and shredding, your very foundation is the fretboard. As a guitarist, therefore, you should really know your fretboard. Luckily, it's really easy to gain knowledge of all different Modes, how they are played, where you find specific notes, and how to play your favourite keys and modes on the 4th, 9th or 15th fret - or basically, wherever you want.
All you need to do, is to learn the following 7 finger position diagrams by heart. Yes, this may take a few days, but it's a small price to pay compared to what you get.
Figure 1
Nr 3 [E] Nr 4 [F] Nr 5 [G] Nr 6 [A]
Phrygian Lydian Mixolydian Aolian
▪|-▪-----▪-- |-▪-----▪-----▪-- |-▪-----▪-----▪- |----▪-----▪--▪•---
▪|-▪•----▪-- |[▪]----▪-----▪-- |[▪]----▪--▪---- |----▪--▪-----▪----
▪|----▪----- |----▪-----▪--▪•- |----▪--▪•----▪- |[▪]-▪•----▪-------
▪|----▪--▪-- |----▪--▪-----▪-- |-▪-----▪-----▪- |----▪-----▪-----▪-
▪|----▪--▪•- |----▪--▪•----▪-- |-▪•----▪-----▪- |----▪-----▪--▪----
▪|-▪-----▪-- |-▪-----▪-----▪-- |-▪-----▪-----▪- |----▪-----▪--▪•---
0 1 3 └ 1 3 5 └ 3 5 7 └ 5 7 9
Nr 7 [B] Nr 1 [C] Nr 2 [D] Nr 3 [E]
Locrian Ionian Dorian Phrygian
|-▪--▪•----▪- |-▪•----▪-----▪- |-▪-----▪--▪---- |-▪--▪-----▪--
|----▪-----▪- |[▪]----▪-----▪- |-▪-----▪--▪•--- |-▪--▪•----▪--
|-▪-----▪--▪- |----▪--▪-----▪- |-▪-----▪------- |-▪-----▪-----
|-▪-----▪--▪• |----▪--▪•----▪- |-▪•----▪-----▪- |-▪-----▪--▪--
|-▪--▪-----▪- |-▪-----▪-----▪- |-▪-----▪-----▪- |-▪-----▪--▪•-
|-▪--▪•----▪- |-▪•----▪-----▪- |-▪-----▪--▪---- |-▪--▪-----▪--
└ 7 9 10 └ 8 10 12 └ 10 12 14 └ 12 14 15
(▪ = relative finger position, [▪] = alternative position, • keynote)
Note: The fret numbers below the guitar tab (and the corresponding mode, given in square brackets next to "Nr") describe C major. This is only for easier understanding - if you know the finger positions, you can play any mode you want.
The 7 diagrams represent the church modes. The modes are independent from certain frets, but once you memorized them you'll be able to play every key you can imagine. The modes are (ignore the square brackets at first):
Figure 2
* Ionian (aka Major Scale) [ 3/4 7/8 FFhFFFh]
* Dorian [ 2/3 6/7 FhFFFhF]
* Phrygian [ 1/2 5/6 hFFFhFF]
* Lydian [ 4/5 7/8 FFFhFFh]
* Mixolydian [ 3/4 6/7 FFhFFhF]
* Aeolian (aka Natural Minor Scale) [ 2/3 5/6 FhFFFhF]
* Locrian [1/2 4/5 hFFhFFF]
When you start playing the guitar, you usually start with C Major scale on the lower end of the fretboard (including open strings). Talking about church modes, this would be E Phrygian. Why E you ask? Shouldn't a Major scale be Ionian?
It's simple: When you play [Note][Mode] (like E Phrygian), then [Note] is always the very first note you play. However, if you play in C Major scale (C Ionian), beginning with the open E string, you simply don't start playing a C note - hence, if you wanna play C Major while starting with an open E string, you naturally don't play C Ionian (since you begin with an E) or E Ionian (since this would be E Major then), but E Phrygian.
Why Phrygian? We now know: If you play C Ionian (C Major), you begin with a C. E.g., you start with the 10th fret on the E string (see Fig. 1, No 7). If you wanna reside in C Major scale, but your new solo requires you to play, let's say, 4 frets higher, the first note you play can't obviously be a C again (actually, it's an E). Since the keynote changes, the Ionian scale in Fig. 1 would bring you out of C Major. Therefore, the finger-positions change - to the church mode which starts 4 frets (or half-tones) higher. Look at Fig. 1 and viola: It must be Phrygian (E Phrygian).
Every mode (except exotic ones) is basically picking 7 tones from the chromatic scale (which consists of 12 half-tones, which are one full octave), and choosing specific intervals. The intervals for the Major scale (or Ionian) is
full-full-half-full-full-full-half
C D E F G A H C
Alternative explanation: So the half-tone steps are between 3/4 and 7/8. If you play C Major and you begin with C, everything's perfectly fine - you're playing C Ionian. But if you wanna play C Major and begin with E, things change. If you play E and follow the scale above, you get E Major. If you want to reside in C Major, you have to change the intervals to F-H-F-F-F-H-F (which is, shifting the intervals one note). So the half-tone steps for C Major (if you start with E), are at 2/3 and 6/7. This is exactly what we call Phrygian (look at the square brackets in Fig. 2!).
Implicitely, if you play C Major starting with the open E string, and play that scale throughout one whole octave, you will run through every single church mode sequentially before again returning to Ionian, where naturally the first note you play is C again.
Playing E major throughout the fretboard, it'll look like this:
D|---1-2---4---6-7---9---
A|-0---2---4---6-7---9---
E|-0---2---4-5---7---9---
\Ionian-/ . . .
\Dor.-/ . .
\Phry./ .
\Lydian-/
Beginning with fret 0, we play E Ionian. If we want to begin with fret 2, we play F-sharp Dorian. If we start with fret 4, we play G-sharp phrygian, and so on.
Enough theory: All you need is here..
- Look again at the figure below. Note, that there are no fret numbers - everything you need to know, are the relative finger positions. This way, you can place your finger on any fret you want playing #1, and you can be sure you're playing in the scale of your keynote (which is, the first note in the Ionian mode, and every note in Fig. 1 having a round dot nearby).
- If you want to reside in that scale, but play on a different fret, choose the correct finger position diagram, and you're done.
- Once you know the diagrams by heart, you always know what scale you are playing in just by recognizing the keynotes (dots in the Figure).
Figure 1 again (positions only)
#1: Ionian #2: Dorian #3: Phrygian #4: Lydian
|-▪•----▪-----▪- |-▪-----▪--▪---- |-▪--▪-----▪-- |-▪-----▪-----▪--
|[▪]----▪-----▪- |-▪-----▪--▪•--- |-▪--▪•----▪-- |[▪]----▪-----▪--
|----▪--▪-----▪- |-▪-----▪------- |-▪-----▪----- |----▪-----▪--▪•-
|----▪--▪•----▪- |-▪•----▪-----▪- |-▪-----▪--▪-- |----▪--▪-----▪--
|-▪-----▪-----▪- |-▪-----▪-----▪- |-▪-----▪--▪•- |----▪--▪•----▪--
|-▪•----▪-----▪- |-▪-----▪--▪---- |-▪--▪-----▪-- |-▪-----▪-----▪--
#5: Mixolydian #6: Aolian #7: Locrian
|-▪-----▪-----▪- |----▪-----▪--▪•--- |-▪--▪•----▪-
|[▪]----▪--▪---- |----▪--▪-----▪---- |----▪-----▪-
|----▪--▪•----▪- |[▪]-▪•----▪------- |-▪-----▪--▪-
|-▪-----▪-----▪- |----▪-----▪-----▪- |-▪-----▪--▪•
|-▪•----▪-----▪- |----▪-----▪--▪---- |-▪--▪-----▪-
|-▪-----▪-----▪- |----▪-----▪--▪•--- |-▪--▪•----▪-
Conclusion: If you learn the 7 finger position diagrams by heart, you can play every mode and every scale on every fret you can possibly imagine. It really works!
You can download Fig. 1 as PDF here.





{kind=link}
{kind=link}
{kind=link}